





與騰訊、哈工(gōng)大同台競技(jì ),深蘭獲自然語言處理(lǐ)領域國(guó)際頂會NAACL2021冠軍
2021-06-082021年6月6日-11日,自然語言處理(lǐ)(NLP)領域的頂級會議NAACL在線(xiàn)上舉辦(bàn)。深蘭科(kē)技(jì )DeepBlueAI團隊參加了Multi-Hop Inference Explanation Regeneration (TextGraphs-15) 共享任務(wù)比賽,并獲得了第一,該方案多(duō)用(yòng)于科(kē)學(xué)知識問答(dá)等領域。同賽道競技(jì )的還有(yǒu)騰訊、哈爾濱工(gōng)業大學(xué)組成的團隊以及新(xīn)加坡科(kē)技(jì )設計大學(xué)團隊等。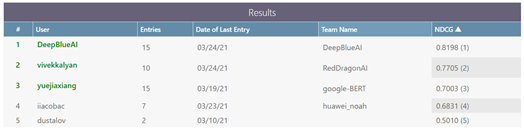
圖1 成績排名(míng)
NAACL全稱為(wèi) Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,與ACL、EMNLP并稱NLP領域的三大頂會。
冠軍方案分(fēn)享
任務(wù)介紹
多(duō)條推理(lǐ)(Multi-Hop Inference)任務(wù)是結合多(duō)條信息去解決推理(lǐ)任務(wù),如可(kě)以從書中(zhōng)或者網絡上選擇有(yǒu)用(yòng)的句子,或者集合一些知識庫的知識去回答(dá)他(tā)人提出的問題。如下圖所示,如需回答(dá)當前問題,要結合圖中(zhōng)所示三種信息才能(néng)完成推理(lǐ),得到正确的答(dá)案。而解釋再生(Explanation Regeneration)任務(wù)是多(duō)條推理(lǐ)任務(wù)的基礎,其目的是構建科(kē)學(xué)問題的解釋,每個解釋都表示為(wèi)一個“解釋圖”,一組原子事實(每個解釋包含1-16個,從9000個事實的知識庫中(zhōng)提取),它們一起構成了對回答(dá)和解釋問題進行推理(lǐ)解析的詳細解釋。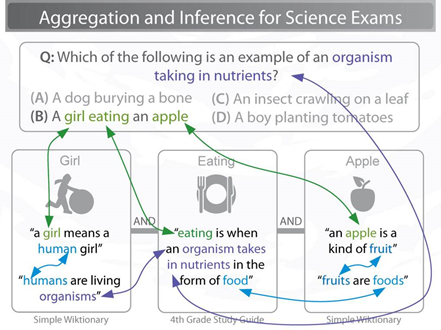
圖2 任務(wù)示例
對于當前任務(wù),舉辦(bàn)方将其定義為(wèi)一個排序任務(wù),輸入的是問題及其對應的正确答(dá)案,要求系統能(néng)夠對提供的半結構化知識庫中(zhōng)的原子事實解釋進行排序,以便排名(míng)靠前的原子事實解釋能(néng)夠為(wèi)答(dá)案提供更加詳細和确切的說明。
數 據
此共享任務(wù)中(zhōng)使用(yòng)的數據包含從 AI2 推理(lǐ)挑戰 (ARC) 數據集中(zhōng)提取的大約 5,100 道科(kē)學(xué)考試題,以及從 WorldTree V2.1[2] 解釋中(zhōng)提取的正确答(dá)案的事實解釋語料庫,并在此基礎上增加了專家生成的相關性評級。支持這些問題及其解釋的知識庫包含大約 9,000 個事實,知識庫既可(kě)以作(zuò)為(wèi)純文(wén)本句子(非結構化)也可(kě)以作(zuò)為(wèi)半結構化表格使用(yòng)。
方 案
該任務(wù)為(wèi)一個排序任務(wù),具(jù)體(tǐ)表現為(wèi)給定問題和答(dá)案,将知識庫中(zhōng)的9,000個原子事實解釋進行排序,評價方式為(wèi)NDCG。方案主要由召回和排序兩部分(fēn)組成,第一步先召回Top-K(k> 100)個解釋,第二步對召回的Top-K個解釋進行排序。針對召回和排序任務(wù),如果直接采用(yòng) Interaction-Based(交互型,即問題文(wén)本和事實解釋在模型中(zhōng)存在信息交互) 類型的網絡,計算量将巨大,因此交互型網絡在當前的任務(wù)中(zhōng)無法使用(yòng),團隊最終采用(yòng)了向量化檢索的方式進行排序。
為(wèi)了提取更深的語義信息生成比較好的特征向量,團隊沒有(yǒu)采用(yòng)TF-IDF、BM25、DSSM[3]等常用(yòng)的排序模型,而是采用(yòng)了當前比較流行的預訓練模型作(zuò)為(wèi)特征提取器,結合Triplet loss[4]訓練了一個Triplet Network來完成向量化排序,其中(zhōng)在召回部分(fēn)和排序部分(fēn)均采用(yòng)Triplet Network。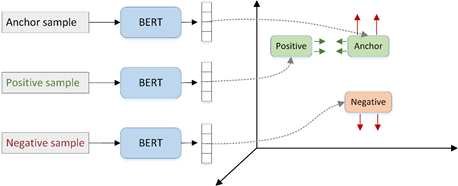
圖3 Triplet loss

模 型
針對當前任務(wù),如下圖所示,錨點(Anchor)樣本為(wèi)問題和答(dá)案連接的文(wén)本,正樣本(Positive)為(wèi)問題對應的解釋文(wén)本,負樣本(Negative)為(wèi)其他(tā)随機選擇與正樣本不同的解釋文(wén)本,其中(zhōng)他(tā)們三個輸入共享一套預訓練語言模型(Pre-trained language model :PLM)參數。訓練時将上述三個文(wén)本輸入到PLM模型中(zhōng),選取PLM模型的所有(yǒu)Token 向量平均作(zuò)為(wèi)輸出,将三個輸入向量經過Triplet Loss 得到損失值完成模型的訓練。
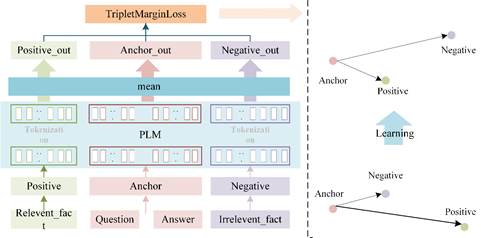
圖4 模型圖
負 采 樣
為(wèi)了更好地訓練模型,團隊在召回階段采用(yòng)了三種不同的負采樣方式:
全局随機負采樣,即在9,000個解釋文(wén)本中(zhōng)随機選取一個不是正樣本的樣本作(zuò)為(wèi)負樣本;
Batch内負采樣,即在當前Batch内選取其他(tā)問題的對應的解釋正樣本,作(zuò)為(wèi)當前問題的負樣本;
相近樣本負采樣,在同一個表中(zhōng)随機選取一個樣本作(zuò)為(wèi)負樣本,因為(wèi)同一個表中(zhōng)的樣本比較相近。
在排序階段同樣采取了三種不同的負采樣方式:
Top-K 随機負采樣,即在在召回的Top-K個樣本中(zhōng)随機選取一個負樣本;
Batch内負采樣,和召回階段相同;
Top-N 随機負采樣,為(wèi)了強化前面一些樣本的排序效果,增大了前面N個樣本的采樣概率(N遠(yuǎn)遠(yuǎn)小(xiǎo)于K)。
實 驗
團隊采用(yòng)了兩種預訓練模型RoBERTa[5] 和ERNIE 2.0[6],并将兩個模型的預測結果進行了融合。在召回和排序階段,采用(yòng)了同樣的參數,主要參數如采用(yòng)三種負采樣方式,每種負采樣方式選取16個樣本,最終的batch size為(wèi)48,epoch為(wèi)15。同時,使用(yòng)了Adam優化器并采用(yòng)了學(xué)習率衰減策略,從1e-5衰減到0。
團隊分(fēn)别評測了NDCG @100、NDCG @500、NDCG @1000、NDCG @2000的結果,最終效果如下表所示,其中(zhōng)Baseline為(wèi)TFIDF模型、Recall為(wèi)召回階段、Re-ranker為(wèi)針對召回的結果重新(xīn)排序的結果。從表中(zhōng)可(kě)以看出基于預訓練模型的方法對比Baseline有(yǒu)着很(hěn)大的提升,同時重排也有(yǒu)着顯著的提升,同時從排行榜中(zhōng)可(kě)以看出DeepBlueAI團隊的模型對比他(tā)人也有(yǒu)着較大的領先。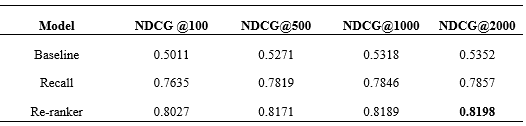
Table 1 The final results compared with different models
參考文(wén)獻
[1] Clark P, Cowhey I, Etzioni O, et al. Think you have solved question answering? try arc, the ai2 reasoning challenge[J]. arXiv preprint arXiv:1803.05457, 2018.
[2] Xie Z, Thiem S, Martin J, et al. Worldtree v2: A corpus of science-domain structured explanations and inference patterns supporting multi-hop inference[C]//Proceedings of The 12th Language Resources and Evaluation Conference. 2020: 5456-5473.
[3] Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrough data." *Proceedings of the 22nd ACM international conference on Information & Knowledge Management*. 2013.
[4] Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering." *Proceedings of the IEEE conference on computer vision and pattern recognition*. 2015.
[5] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[6] Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 8968-8975.
-

8項冠亞季軍收官ECCV2020,深蘭獲三大視覺頂會挑戰賽大滿貫
計算機視覺 -
與騰訊、哈工(gōng)大同台競技(jì ),深蘭獲自然語言處理(lǐ)領域國(guó)際頂會NAACL2021冠軍
計算機視覺 -

捷報 | 深蘭科(kē)技(jì )“雙隊”出征CVPR2021 斬獲五冠共獲14項大獎
計算機視覺 -

2022CVPR傳捷報丨深蘭科(kē)技(jì )再度折桂,連續4屆獲得CVPR挑戰賽冠軍
計算機視覺 -

深蘭科(kē)技(jì )奪冠CCKS2022“帶條件的分(fēn)層級多(duō)答(dá)案問答(dá)”評測任務(wù)競賽
自然語言處理(lǐ) -
PK 656 個對手!深蘭科(kē)技(jì )在全球頂級AI賽事kaggle競賽中(zhōng)再次奪冠
計算機視覺 -

一冠三亞二季!深蘭科(kē)技(jì )在EMNLP2022國(guó)際頂級賽事再創佳績
數據挖掘 -

6個獎項!深蘭科(kē)技(jì )在CVPR 2023挑戰賽中(zhōng)再獲佳績
計算機視覺 -

6冠3亞2季!深蘭科(kē)技(jì )在RANLP2023國(guó)際賽事上斬獲11項大獎
計算機視覺