





EMNLP2021 | 深蘭DeepBlueAI團隊少量數據關系抽取論文(wén)被錄用(yòng)
2021-11-09近日,EMNLP 2021在官網提前公(gōng)布了今年的論文(wén)審稿結果,深蘭DeepBlueAI團隊論文(wén)《MapRE: An Effective Semantic Mapping Approach for Low-resource Relation Extraction》被錄用(yòng)。該論文(wén)提出了在低資源關系提取任務(wù)中(zhōng)融合同類别樣本間句子相關性信息和關系标簽語義兩個方面的信息的方法,并在多(duō)個關系提取類任務(wù)的公(gōng)開數據集的實驗中(zhōng)得到了SOTA結果。
EMNLP(全稱Conference on Empirical Methods in Natural Language Processing)是國(guó)際自然語言處理(lǐ)頂級會議,由ACL SIGDAT主辦(bàn),每年舉辦(bàn)一次,在Google Scholar計算語言學(xué)刊物(wù)指标中(zhōng)排名(míng)第二,主要關注統計機器學(xué)習方法在自然語言處理(lǐ)領域的應用(yòng)。近幾年随着大規模數據的機器學(xué)習方法的發展,該會議人數逐年增加,受到越來越廣泛地關注。
EMNLP論文(wén)入選标準極為(wèi)嚴格,EMNLP 2021共收到有(yǒu)效投稿3114篇,錄用(yòng)754篇,錄用(yòng)率僅為(wèi)24.82%。按照慣例,EMNLP 2021評選了最佳長(cháng)論文(wén)、最佳短論文(wén)、傑出論文(wén)和最佳Demo論文(wén)四大獎項,共7篇論文(wén)入選。
今年EMNLP 2021 将于11月7日 - 11日在多(duō)米尼加共和國(guó)蓬塔卡納和線(xiàn)上聯合舉辦(bàn),會議為(wèi)期五天,複旦大學(xué)計算機科(kē)學(xué)學(xué)院教授黃萱菁将擔任本次會議的程序主席。在即将召開的EMNLP學(xué)術會議上将展示自然語言處理(lǐ)領域的前沿研究成果,這些成果也将代表着相關領域和技(jì )術細分(fēn)中(zhōng)的研究水平以及未來發展方向。
深蘭DeepBlueAI團隊的論文(wén)提出了在低資源關系提取任務(wù)中(zhōng)融合同類别樣本間句子相關性信息和關系标簽語義兩個方面信息的方法,并在多(duō)個關系提取類任務(wù)的公(gōng)開數據集的實驗中(zhōng)得到了SOTA結果。
關系提取旨在發現給定句子中(zhōng)兩個實體(tǐ)之間的正确關系,是NLP中(zhōng)的一項基本任務(wù)。該問題通常被視為(wèi)有(yǒu)監督的分(fēn)類問題,由大規模标記數據進行訓練。近年來,關系提取模型得到了明顯的發展。然而,訓練樣本過少時,模型性能(néng)會急劇下降。
在最近工(gōng)作(zuò)中(zhōng),深蘭DeepBlueAI團隊利用(yòng)小(xiǎo)樣本學(xué)習的進步來解決低資源問題。少樣本學(xué)習的關鍵思想是學(xué)習一個用(yòng)來比較query和support set samples中(zhōng)樣本相似度的模型,這樣,關系抽取的目标從學(xué)習一個通用(yòng)的、準确的關系分(fēn)類器變為(wèi)學(xué)習一個将具(jù)有(yǒu)相同關系的實例映射到相近區(qū)域的映射模型。
在少樣本學(xué)習的設定下,标簽信息,即包含關系本身語義知識的關系标簽,在訓練和預測時并沒有(yǒu)被模型用(yòng)到。深蘭DeepBlueAI團隊的實驗結果表明,在預訓練和微調中(zhōng)結合上述标簽信息和各關系類别的樣本兩類映射可(kě)以顯着提高模型在少樣本關系提取任務(wù)上的表現。
01
語義映射預訓練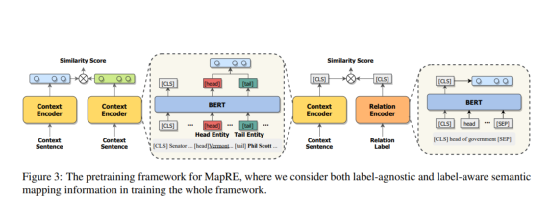
預訓練部分(fēn)的目标函數由三個部分(fēn)組成:
CCR: 樣本表示間損失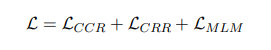
CRR:樣本與标簽間損失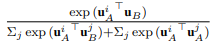
MLM:語言模型損失,同BERT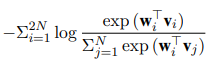
深蘭DeepBlueAI團隊采取類似CP (Peng et al., 2020)的方法中(zhōng)對模型進行預訓練。不同之處在于團隊還考慮了标簽信息,使用(yòng)Wikidata作(zuò)為(wèi)預訓練語料庫,去除了Wikidata和DeepBlueAI團隊用(yòng)于後續實驗的數據集之間的重複部分(fēn)。
本部分(fēn)中(zhōng),深蘭DeepBlueAI團隊使用(yòng)BERT base作(zuò)為(wèi)基礎模型,采用(yòng)AdamW優化器,最大輸入長(cháng)度設置為(wèi)60。深蘭DeepBlueAI團隊共訓練了11,000步,其中(zhōng)前500步為(wèi)warmup,batch size設為(wèi)2040,學(xué)習比率為(wèi)3e-5。
02
監督性關系抽取
本部分(fēn)深蘭DeepBlueAI團隊一共試驗了MapRE預訓練模型的兩種使用(yòng)方式,即MapRE-L(直接使用(yòng)全連接層對文(wén)本編碼輸出預測關系)和MapRE-R(采用(yòng)關系編碼器編碼關系标簽,再做相似度匹配),模型結構如圖: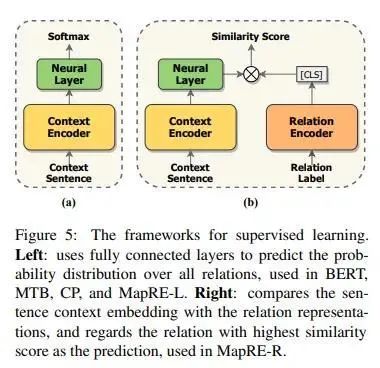
在監督性關系抽取任務(wù)中(zhōng)深蘭科(kē)技(jì )評估兩個基準數據集:ChemProt和Wiki80。前者包括56,000個實例和80種關系,後者包括10,065個實例和13種關系。
實驗結果如下: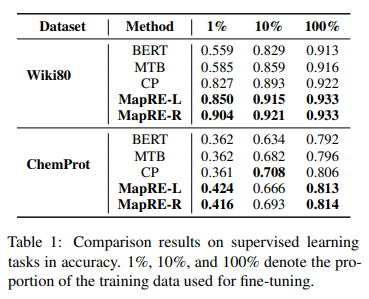
這裏深蘭DeepBlueAI團隊重點關注低資源關系抽取,選取以下三個有(yǒu)代表性的模型進行比較。
1)BERT:該模型在文(wén)本的頭實體(tǐ)和尾實體(tǐ)部分(fēn)分(fēn)别增加特殊的标記token,在BERT輸出後接幾個全連接層用(yòng)于關系分(fēn)類。
2)MTB (Soares et al., 2019):MTB模型假設無監督數據中(zhōng)頭實體(tǐ)和尾實體(tǐ)相同的句子均為(wèi)正樣本對,即具(jù)有(yǒu)相同的關系。在測試階段,對query和support set的相似度得分(fēn)進行排名(míng),将得分(fēn)最高的關系作(zuò)為(wèi)預測結果。
3)CP (Peng et al., 2020):同MTB類似,我們的方法同CP模型的不同點在于,我們在預訓練和微調時均考慮了标簽信息。
我們可(kě)以觀察到:
1)在BERT上進行預訓練(即MTB, CP和MapRE)可(kě)以提高模型性能(néng)
2)比較MapRE-L與CP和MTB,在預訓練期間添加标簽信息可(kě)以顯着提高模型性能(néng),尤其是在資源極少的情況下,例如僅1%的訓練集用(yòng)于微調
3) 比較 MapRE-R 和 MapRE-L,其中(zhōng)前者在微調中(zhōng)也考慮了标簽信息,表現出更好更穩定的實驗結果
結果表明在預訓練和微調中(zhōng)使用(yòng)标簽信息均可(kě)顯著提高低資源監督性關系抽取任務(wù)上的模型性能(néng)。
03
少樣本與零樣本關系抽取
在少樣本學(xué)習的情況下,模型需要在隻有(yǒu)給定一定關系類别,每個類别少數樣本的情況下進行預測。對于N way K shot問題,Support set S包含N個關系,每個關系有(yǒu)K個樣本,查詢集包含Q個樣本,每個樣本屬于 N 個關系之一。
該模型結構如下: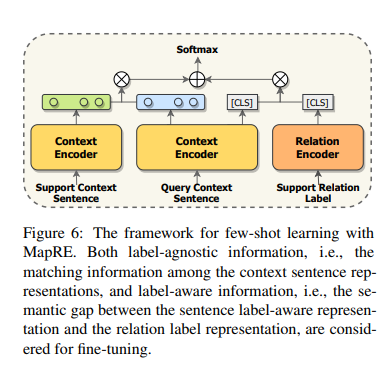
模型預測結果由下式得出: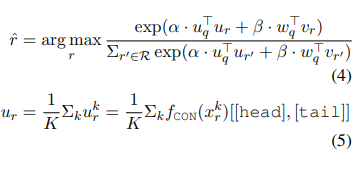
深蘭DeepBlueAI團隊在兩個數據集上評估提出的方法:FewRel和NYT-25。FewRel 數據集包含70,000個句子和100個關系(每個關系有(yǒu)700個句子),數據來源為(wèi)維基百科(kē)。其中(zhōng)64個關系用(yòng)于訓練,16個用(yòng)于驗證,以及20個用(yòng)于測試。測試數據集包含 10,000 個句子,必須在線(xiàn)評估。NYT-25數據集是由Gao et al., 2019。DeepBlueAI團隊随機抽取 10 個關系用(yòng)于訓練,5 個用(yòng)于驗證,10 個用(yòng)于測試。
實驗結果如下: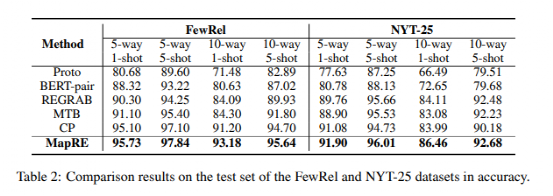
如上表所示,在所有(yǒu)的實驗設置下,深蘭DeepBlueAI團隊提出的MapRE,由于在預訓練和微調中(zhōng)均考慮了support set樣本句子和關系标簽信息,提供了穩定的性能(néng)表現,并大幅優于一系列baseline方法。結果證明了團隊提出的框架的有(yǒu)效性,并表明了關系抽取中(zhōng)關系标簽語義映射信息的重要性。
深蘭DeepBlueAI團隊進一步考慮了低資源關系抽取的極端條件,即零樣本的情況。在該設定下,模型輸入不包含任何support set樣本。在零樣本條件下,以上大部分(fēn)少樣本關系抽取框架不适用(yòng),因為(wèi)其它該類模型的每個關系類别中(zhōng)至少需要有(yǒu)一個樣本。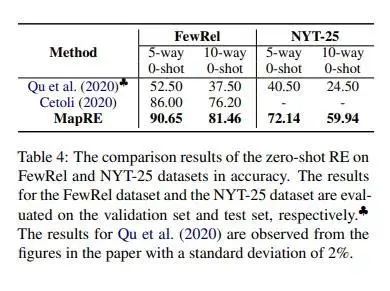
結果表明,與其它最近零樣本學(xué)習工(gōng)作(zuò)相比,深蘭DeepBlueAI團隊提出的MapRE在所有(yǒu)設定下都獲得了出色的表現,證明了MapRE的有(yǒu)效性。
總結
在這項工(gōng)作(zuò)中(zhōng),深蘭DeepBlueAI團隊提出了一種同時考慮标簽信息和樣本信息的關系抽取模型,MapRE。大量實驗結果表明,MapRE模型對監督性關系抽取、少樣本關系抽取和零樣本關系抽取任務(wù)中(zhōng)展示了出色的表現。結果表明樣本和标簽信息兩者在預訓練和微調中(zhōng)都起到了重要作(zuò)用(yòng)。在這項工(gōng)作(zuò)中(zhōng),深蘭DeepBlueAI團隊沒有(yǒu)研究領域遷移造成的潛在影響,我們将相關分(fēn)析作(zuò)為(wèi)下一步的工(gōng)作(zuò)。
綜上,深蘭DeepBlueAI團隊提出的MapRE模型結合了零樣本和少樣本學(xué)習的特點,結合了同關系樣本和關系語義兩個方面的信息,目前已在深蘭科(kē)技(jì )智能(néng)數據标注平台文(wén)本關系抽取功能(néng)中(zhōng)得以應用(yòng),大幅提升了模型在少量訓練樣本下的表現,在數據的智能(néng)标注等領域可(kě)大幅節省人力,提升标注效率及标注質(zhì)量。
-

8項冠亞季軍收官ECCV2020,深蘭獲三大視覺頂會挑戰賽大滿貫
計算機視覺 -
與騰訊、哈工(gōng)大同台競技(jì ),深蘭獲自然語言處理(lǐ)領域國(guó)際頂會NAACL2021冠軍
計算機視覺 -

捷報 | 深蘭科(kē)技(jì )“雙隊”出征CVPR2021 斬獲五冠共獲14項大獎
計算機視覺 -

2022CVPR傳捷報丨深蘭科(kē)技(jì )再度折桂,連續4屆獲得CVPR挑戰賽冠軍
計算機視覺 -

深蘭科(kē)技(jì )奪冠CCKS2022“帶條件的分(fēn)層級多(duō)答(dá)案問答(dá)”評測任務(wù)競賽
自然語言處理(lǐ) -
PK 656 個對手!深蘭科(kē)技(jì )在全球頂級AI賽事kaggle競賽中(zhōng)再次奪冠
計算機視覺 -

一冠三亞二季!深蘭科(kē)技(jì )在EMNLP2022國(guó)際頂級賽事再創佳績
數據挖掘 -

6個獎項!深蘭科(kē)技(jì )在CVPR 2023挑戰賽中(zhōng)再獲佳績
計算機視覺 -

6冠3亞2季!深蘭科(kē)技(jì )在RANLP2023國(guó)際賽事上斬獲11項大獎
計算機視覺