





賽道 | 深蘭科(kē)技(jì )折桂 2021SemEval,雙賽道比拼中(zhōng)獲得“兩冠一亞”
2021-08-01SemEval是由國(guó)際計算語言學(xué)協會(Association for Computational Linguistics,ACL)主辦(bàn)的國(guó)際語義評測大賽, SemEval是全球範圍内影響力最強、規模最大、參賽人數最多(duō)的語義評測競賽。自2001年起,SemEval已成功舉辦(bàn)十五屆,吸引了卡内基梅隆大學(xué)、哈工(gōng)大、中(zhōng)科(kē)院、微軟和百度等國(guó)内外一流高校、頂級科(kē)研機構和知名(míng)企業參與。
8 月 1 日- 6 日,SemEval2021與ACL-IJCNLP 2021 在泰國(guó)曼谷共同舉辦(bàn)。深蘭科(kē)技(jì )作(zuò)為(wèi)人工(gōng)智能(néng)頭部企業,參加了“詞彙複雜度預測(任務(wù)一)”和“幽默性和冒犯性文(wén)本識别與評估(任務(wù)七)”兩個大任務(wù)中(zhōng)的6個子任務(wù),最終獲得2項第一、1項第二、1項第三,共計4項top3。團隊在賽事中(zhōng)運用(yòng)的相關技(jì )術和模型已成功應用(yòng)于公(gōng)司的自動化機器學(xué)習平台中(zhōng)。
賽事介紹
任務(wù)一Lexical Complexity Prediction (LCP)
任務(wù)一為(wèi)上下文(wén)中(zhōng)詞彙的複雜度預測任務(wù),任務(wù)分(fēn)為(wèi)兩個子任務(wù),子任務(wù)1為(wèi)預測單個單詞的複雜度,子任務(wù)2為(wèi)預測詞組(多(duō)詞表達)的複雜度。其中(zhōng)數據樣例如下:
Table 1 數據樣例
結合數據可(kě)以看出當前任務(wù)為(wèi)一個回歸任務(wù),即基于上下文(wén)預測給定詞彙的複雜度,深蘭團隊在兩個子任務(wù)的排名(míng)如下,團隊在子任務(wù)1獲得了第二名(míng),在子任務(wù)2中(zhōng)獲得了第一名(míng)。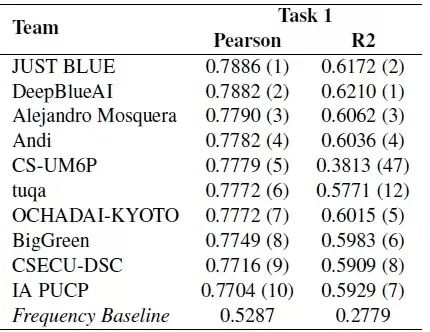
子任務(wù)1 成績排名(míng)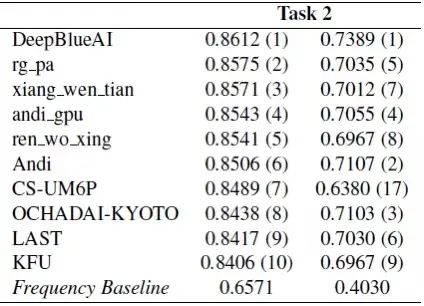
子任務(wù)2 成績排名(míng)
任務(wù)七HaHackathon: Detecting and Rating Humor and Offense
任務(wù)七為(wèi)幽默性和冒犯性文(wén)本識别與評估任務(wù),也是首次将幽默性和冒犯性識别結合起來的任務(wù),因為(wèi)文(wén)本對一些用(yòng)戶來說是幽默的,但是對其他(tā)用(yòng)戶來說可(kě)能(néng)是冒犯的,舉辦(bàn)方共将任務(wù)劃分(fēn)為(wèi)幽默性識别和冒犯性識别,其中(zhōng)幽默性識别又(yòu)被劃分(fēn)為(wèi)三個子任務(wù),共計4個子任務(wù),分(fēn)别為(wèi):
子任務(wù)1a:預測文(wén)本是否會被視為(wèi)幽默,為(wèi)二分(fēn)類任務(wù);
子任務(wù)1b:如果文(wén)本被歸類為(wèi)幽默,預測它的幽默程度,為(wèi)回歸任務(wù);
子任務(wù)1c:如果文(wén)本被歸類為(wèi)幽默,預測當前幽默評級是否有(yǒu)争議,二分(fēn)類任務(wù);
子任務(wù)2a:預測文(wén)本的冒犯程度,為(wèi)回歸任務(wù)
深蘭團隊同時參加了4個任務(wù),其中(zhōng)在任務(wù)1a、1c、2a取得了較好的成績,在子任務(wù)2a中(zhōng)獲得了第一名(míng),在子任務(wù)1a中(zhōng)獲得了第三名(míng),在子任務(wù)1c中(zhōng)獲得了第五名(míng)。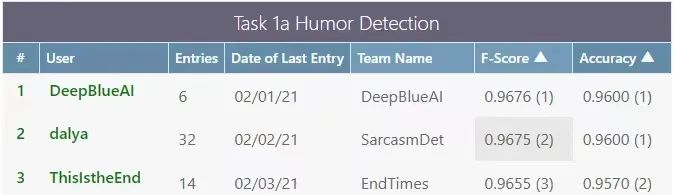
Task 1a 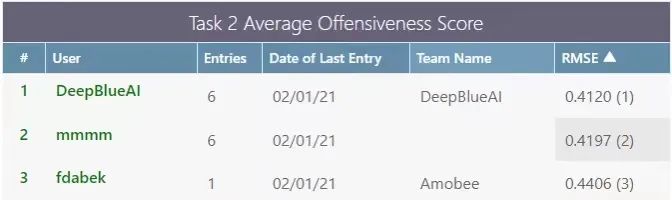
Task 2a
方案
上述幾個任務(wù)都是标準的分(fēn)類任務(wù)或者回歸任務(wù),深蘭團隊采取了統一的模型和訓練方案,半自動化的完成模型的訓練和融合。模型采用(yòng)當前主流的預訓練模型,如BERT,基于預訓練模型構建分(fēn)類和回歸模型,模型圖如下: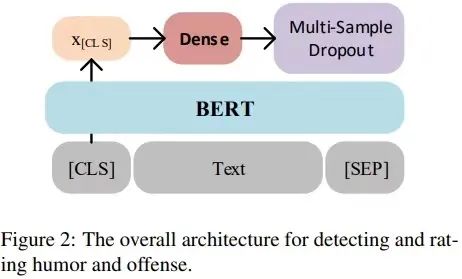
模型圖
模型主要分(fēn)為(wèi)以下幾個部分(fēn),文(wén)本輸入、CLS向量加權平均、全連接、Multi-sample dropout:
文(wén)本輸入針對句子級别分(fēn)類或者回歸模型,一般為(wèi)單個句子輸入或者兩個句子。例如對于上述Task7為(wèi)單個句子輸入,而對于Task1則需要變成兩個句子輸入,句子一為(wèi)待識别的詞,句子二為(wèi)上下文(wén)文(wén)本。
BERT有(yǒu)兩個特殊的标示符,分(fēn)别是[CLS]、[SEP],其中(zhōng)[CLS]在訓練的時候,用(yòng)在Next Sentence Prediction任務(wù)上,[CLS]可(kě)以代表整個句子的語義表示,[CLS]通常用(yòng)在句子級别的分(fēn)類任務(wù)上。當前任務(wù)也是句子級别的分(fēn)類任務(wù),深蘭團隊的模型也是采取[CLS]位置的向量進行分(fēn)類。為(wèi)了提取更深層次的語義特征,深蘭團隊不僅僅用(yòng)BERT最後一層的輸出,而是選取多(duō)層[CLS]位置向量進行加權平均,來代表整個句子的語義表示。
Multi-sample dropout 是dropout的一種變種,傳統 dropout 在每輪訓練時會從輸入中(zhōng)随機選擇一組樣本(稱之為(wèi) dropout 樣本),而 multi-sample dropout 會創建多(duō)個 dropout 樣本,然後平均所有(yǒu)樣本的損失,從而得到最終的損失,multi-sample dropout 共享中(zhōng)間的全連接層權重。通過綜合 M個dropout 樣本的損失來更新(xīn)網絡參數,使得最終損失比任何一個 dropout 樣本的損失都低。這樣做的效果類似于對一個minibatch中(zhōng)的每個輸入重複訓練 M 次。因此,它大大減少訓練叠代次數,從而大幅加快訓練速度。由于大部分(fēn)運算發生在 dropout 層之前的BERT層中(zhōng),Multi-sample dropout 并不會重複這些計算,對每次叠代的計算成本影響不大。實驗表明,multi-sample dropout 還可(kě)以降低訓練集和驗證集的錯誤率和損失。
損失函數,當前模型可(kě)以适用(yòng)于分(fēn)類和回歸任務(wù),隻需改變損失函數即可(kě),對于分(fēn)類任務(wù)主要采用(yòng)的損失函數為(wèi)Cross Entropy 、Binary Cross Entropy、focal loss等,對于回歸任務(wù)主要采用(yòng)的損失函數為(wèi)均方誤差(Mean Square Error, MSE)、平均絕對誤差(Mean Absolute Error, MAE)等。
方案流程解讀
基于上述模型,深蘭的方案流程為(wèi):
1、選擇合适的預訓練模型,首先基于構建好的baseline選取多(duō)種預訓練模型進行測試,如BERT、RoBERTa、ALBERT、ERNIE等,之後選取最好的或者幾個比較好的預訓練模型。
2、領域自适應預訓練(DAPT),利用(yòng)在所屬的領域數據上繼續預訓練,例如針對Task1,數據主要來源為(wèi)醫(yī)療、聖經、歐洲議會記錄,則選擇這幾個領域的數據繼續進行掩碼語言模型任務(wù)(MLM),提升預訓練模型在當前領域上的性能(néng)。
3、任務(wù)自适應預訓練(TAPT),在當前和任務(wù)相關的數據集上進行掩碼語言模型(MLM)訓練提升預訓練模型在當前數據集上的性能(néng)。
4、對抗訓練,對抗訓練是一種引入噪聲的訓練方式,可(kě)以對參數進行正則化,從而提升模型的魯棒性和泛化能(néng)力。深蘭團隊采用(yòng)FGM(Fast Gradient Method),通過在嵌入層加入擾動,從而獲得更穩定的單詞表示形式和更通用(yòng)的模型,以此提升模型效果。
5、僞标簽,将測試集打上标簽,并加入到訓練集中(zhōng),增大訓練集的數量,提升最後的效果。
6、知識蒸餾,知識蒸餾由Hinton在2015年提出,主要應用(yòng)在模型壓縮上,通過知識蒸餾将大模型所學(xué)習到的有(yǒu)用(yòng)信息來訓練小(xiǎo)模型,在保證性能(néng)差不多(duō)的情況下進行模型壓縮。深蘭團隊将利用(yòng)模型壓縮的思想,采用(yòng)模型融合的方案,融合多(duō)個不同的模型作(zuò)為(wèi)teacher模型,将要訓練的作(zuò)為(wèi)student模型。
7、模型融合,為(wèi)了更好地利用(yòng)數據,深蘭團隊采用(yòng)7折交叉驗證,針對每個會使用(yòng)了多(duō)種預訓練模型,又(yòu)通過改變不同的參數随機數種子以及不同的訓練策略訓練了多(duō)個模型。最後采用(yòng)線(xiàn)性回歸、邏輯回歸等機器學(xué)習模型進行融合。
總 結
利用(yòng)上述構建的框架,深蘭團隊參加了任務(wù)一和任務(wù)7共計6個子任務(wù),獲得了4項獎項,充分(fēn)證明了方案的可(kě)行性,并且當前方案相關技(jì )術以及模型成功應用(yòng)于公(gōng)司的自動化機器學(xué)習平台中(zhōng),深蘭自動化機器學(xué)習平台以低門檻、廣覆蓋、高精(jīng)度、少成本的優勢,為(wèi)各個行業領域提供核心算法。
-

8項冠亞季軍收官ECCV2020,深蘭獲三大視覺頂會挑戰賽大滿貫
計算機視覺 -
與騰訊、哈工(gōng)大同台競技(jì ),深蘭獲自然語言處理(lǐ)領域國(guó)際頂會NAACL2021冠軍
計算機視覺 -

捷報 | 深蘭科(kē)技(jì )“雙隊”出征CVPR2021 斬獲五冠共獲14項大獎
計算機視覺 -

2022CVPR傳捷報丨深蘭科(kē)技(jì )再度折桂,連續4屆獲得CVPR挑戰賽冠軍
計算機視覺 -

深蘭科(kē)技(jì )奪冠CCKS2022“帶條件的分(fēn)層級多(duō)答(dá)案問答(dá)”評測任務(wù)競賽
自然語言處理(lǐ) -
PK 656 個對手!深蘭科(kē)技(jì )在全球頂級AI賽事kaggle競賽中(zhōng)再次奪冠
計算機視覺 -

一冠三亞二季!深蘭科(kē)技(jì )在EMNLP2022國(guó)際頂級賽事再創佳績
數據挖掘 -

6個獎項!深蘭科(kē)技(jì )在CVPR 2023挑戰賽中(zhōng)再獲佳績
計算機視覺 -

6冠3亞2季!深蘭科(kē)技(jì )在RANLP2023國(guó)際賽事上斬獲11項大獎
計算機視覺